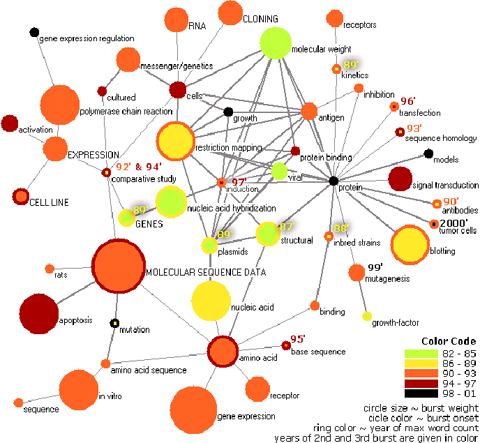
One idea
背景:
在过去的教学中,老师平时会总结一些知识网络图谱来反映知识之间的联系,当然还有方法的总结等等。但是都是一个小范围的总结,很难做到全盘的总结,因为关系太复杂了,很难由一个人来总结。所以即使一个数学很强的人,也很难还原整个体系结构,因为人脑不能以下考虑这么多因素和这么多个点。但是计算机最大优势就在于它的运算能力。
目标:
我希望能够描述一个知识点在整个知识森林中的位置。目前希望至少能够包含两个方面的信息:一个是本知识的纵向联系,二是本知识与其他知识的横向关联。
现在我考虑把老师总结的知识之间的基本关系按照一定的规则存入数据库中,然后根据一定的规则发现所有知识之间的关系。我的目的是希望能够构建一张图,能够反映整个知识体系的结构,首先是知识的层次关系,然后是横向联系等。
方法:
现在我们假设:我们要通过测试发现学生的在数学这门课程上的知识漏洞,那么首先我们自己需要一个数学这门课的一个整体知识体系结构(高中的,不用想得那么复杂)。那么这个知识体系是由国家规定的考纲来确定。
我们假设:
(1)考纲的能力等级表示所要求能力的等级,要求越高说明重要性越大;
(2)知识点被其它知识点引用的次数越多表示越基础;
这样以每个知识点为一个节点(Node),节点间的连线表示引用方向(Direct),节点的大小表示引用次数的多少(Numbers of Citation),节点的颜色(Color)表示对本知识点要求掌握的程度。
然后当我们测试的时候,在每个节点下面包含一系列的测试、训练题目和学习素材,通过测试题目我们来考察学生在本知识点的掌握程度,然后通过学习素材和训练题目来弥补这个知识点的问题。题目和素材都按一定的难度级别分类,不同的知识点的要求不同。当存在多个知识点漏洞的时候,我们按照引用次数的多少和颜色判断优先级别,引用次数越多表示越急需改进,颜色也深表是这个点要求掌握的程度越高。
这是今天想出来的一个基本模型。现在还涉及一个知识点的划分粒度的问题。我们知道考纲上的要求还不够详细。计算机计算最大的缺陷就是数据的预处理,质量不高的数据得到的结果可能很糟糕。正在考虑作一个原型系统来看看:
(1)从一个小的章节开始,然后类推。因为一开始做得太大范围太广,可能会对出现问题的点上考虑太多思维陷入混乱。
(2)或者从大的范围粗略划分,做一些要求不太高的测试。然后对知识点细分,不断加节点和分支。
Maybe you can give more advices on it. So why not just think about it?
I am looking forward your valuable advices.
我想可以提高数据的质量
比如,先来一个题库的测试,限定学生知识缺陷的范围,这个可以用时间和正确率来判断;然后通过题目难易程度来提高判断的效率,比如二分法,再想想。。。。
A friend of mine:
对于很难的题目:涉及的知识面广或者知识点深
如果应试者的时间和正确率都不错,就可以排除一些节点的判断,退回上一级目录。直接进入平行一级的知识点的判断。
希望那个得到的目标图形类似这种形式: